Hello today I face a problem with my sublime text 3 editor but it’s pretty fine with my note pad ++
I can’t write Bengali language , seems encoding system UTF-8 is true . What can I do. Anyone know this solution .
Any suggestion also appreciated 
I can't write Bengali language in Sublime text 3
wpsafar
#1
0 Likes
Combining characters in Unicode/Bengali not working
wpsafar
#3
What do you mean by font symbols not clear, sorry .
It’s Bengali languages and working fine with just notepat++ but via encoding UTF-8 but not working in sublime and I check UTF-8 is true on sublime
0 Likes
addons_zz
#4
By symbols I mean, not all System Font Types, have all UTF-8/unicode characthers (or symbols), when some font is missing them, text editors just show some random null character in place.
0 Likes
addons_zz
#6
You can try using on Sublime Text, the same font as you were using on Notepad++. If that does not fixes the issue, then, there is a bug on Sublime Text font engine. Then, you can report this bug on the Sublime Text community issue tracker on:
0 Likes
wbond
#7
We fixed some issues with combing characters in the current dev series. If you are using 3176, then you won’t see the fixes until the next stable release.
0 Likes
Jackeroo
#11
Help => About Sublime Text
As an aside, there are Bengali fonts that you can download. I don’t know if that would solve your problem.
0 Likes
wbond
#12
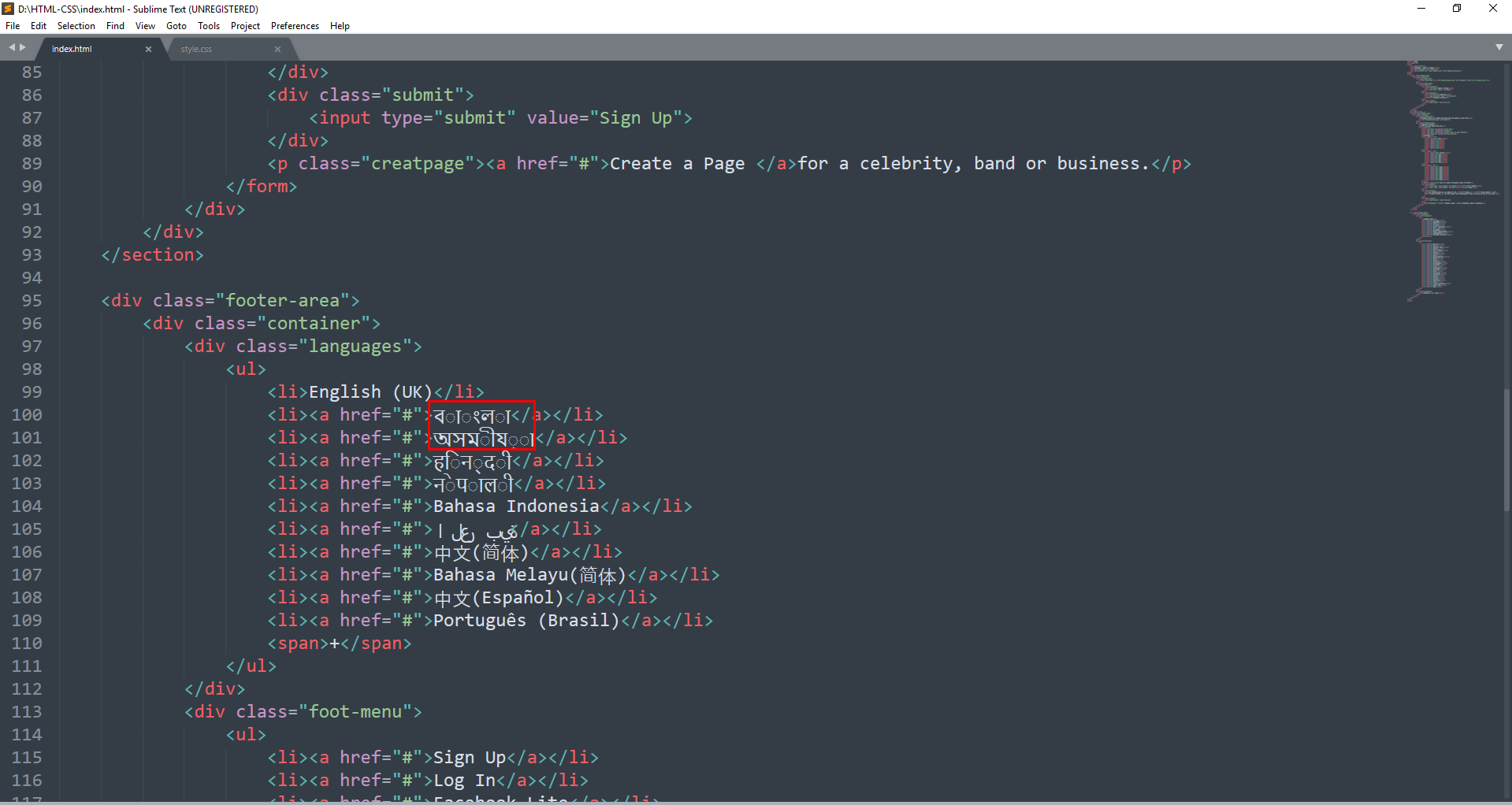
The issue isn’t fonts. If you look at the screenshot you’ll see dotted circles to the left of glyphs. This indicates the character is a combining character, and it is supposed to overlay a glyph to the left. However, before updating our grapheme algorithm, these were being sent individually to the Window font library, and it was returning the standalone representations of the combining characters. I’m fairly sure the screenshot is from build 3176, unless there is another category of combining-like characters in Unicode that I haven’t run across yet.
To my knowledge, build 3188 has an implementation that handles all but two of characters with combining characters (as of Unicode 11). Currently the Thai Sara Am (https://www.compart.com/en/unicode/U+0E33) and Lao Vowel Sign Am (https://www.compart.com/en/unicode/U+0EB3) are not handled properly. This is because Unicode doesn’t classify them as combining characters. Technically they are compound letters that lead with a combining character. Handling of these will be part of a future release.
2 Likes

Jackeroo
#15
Thanks for the clarification. The technical points are way over my head. I guess I should keep out of it.
I am glad that you see a solution to the problem.
0 Likes
wbond
#16
Just to clarify, there isn’t a “free” version, but a version you can evaluate if you want to buy or not.
The fixes are not part of the stable release, which is the only release you can use when evaluating.
3 Likes