So, part of what I’ve been working on is a code beautifier that, more or less, aligns and indents the code properly based on scanning through the source document. So there’s a lot of scanning for keywords and parentheses and things of that nature going on.
It hasn’t escaped my notice that this is to some degree exactly what the syntax file is doing. While it’s been instructive to roll my own, it might be ultimately more efficient to lean on the editor’s own syntax context and scope rules. With that in mind, I’ve been studying the syntax file definition documentation and I’ve come up with a few questions.
-
Am I correct in believing that the scope points are linked to the View object? That is to say, if I subsequently slurp the entire source code file into a string, I’ve then lost all the scope information? I think that must be true, but it’d be interesting if it weren’t.
-
Asssuming 1 to be true, is there an API command to run the syntax scope analysis against a string?
In a different vein, the syntax file I have was created for TextMate a long time ago. It still works well, though I think perhaps some good could be done by getting more fine grained context, so I’ve been mulling over writing my own variation.
-
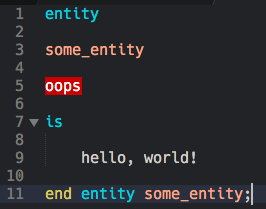
The language I’m working in (VHDL) does not really care much about white space aside from at least some whitespace as a delimeter. It’s also kind of verbose (it’s related to Ada in that way). For example, there is a top level lexical object called an entity (not to be confused with the scope entity). The syntax goes a little like this:
entity <valid_name> is
end entity <valid_name>;
However, as far as the language goes, you could write it as:
entity
<valid_name>
is
end
entity
<valid_name>
;
Now, no one sane does this, but while I think that, I’ve run across a lot of variations on what people actually write out. Am I correct in believing the syntax engine would have a lot of trouble with matching in the extreme variation? If I’m reading it correctly, it says that matches are only ever applied against a single line. So, coping with this variation would require a lot of pushing and popping? Or is there a way to have a match apply over multiple lines?
This by the way is actually one of the errors in the current VHDL syntax language file I believe, though I’ve not figured out exactly how to correct it yet. A procedure body definition might look like this:
procedure <valid_name> [(
<parameter block> )] is
begin
<statements>;
end procedure <valid_name>;
It is completely valid to start the parenthetical parameter block on the next line, however if I do that, the captured name is incorrect and it flags the final line in error.
- Prioritization. The language has a few constructs that are capable of having additional words for different context. So in an entity declaration you may have a
generic ():block. In an instantiation, you may have ageneric map ()block. If I’m trying to write a regex for this, will I need to look forgeneric mapbeforegenericand thus put it higher in the file? There also may be some tricks with context as well I can use as thatmapelement is only ever used in the one place. However I also have a few weird things like some branching contexts. Anassertstatement can have areportclause within it along with aseverityclause. However it’s entirely valid to have areportstatement on its own line completely separate fromassert.
Anyhow, any insight into the nitty gritty of this would be greatly appreciated. I’m going to continue to immerse into the basic syntax document, the unofficial syntax document, and then the scope naming (which is really pretty complex and I can’t say I’ve wholly wrapped my head around exactly which name should be applied in my situation.) Thanks in advance!
 The following toy-syntax perfectly scopes the whole shebang, including giving the body a
The following toy-syntax perfectly scopes the whole shebang, including giving the body a