Hi,
ST2 is a great tool - partially thanks to availability of all the packages. But I have a real concern and there’s one thing that stops me from using (and buying) it: syntax highlighting.
I think that there are two models for syntax highlighting that work:
- token based (used mostly in simple text editors) - the source file is tokenized and then every token is assigned to a group which has a specific colour assigned,
- semantical/contextual (used by large IDEs) - the source is parsed and the tokens are coloured depending on semantic/context of the token.
If I understand correctly, what ST2 is doing is a strange mixture of these two: you can specify a set of regexes that match the input and single matches of that regex are mapped to different tokens.
Sorry to say this, but its… whacky. See the simplest example:
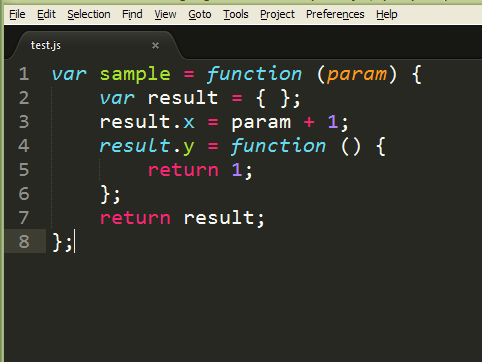
You could say that the package has bugs, but I would say that this approach clearly doesn’t work. I understand that it is inherited from TextMate, but in my opinion this should be changed. Regexes can match a very limited set of languages and what TM/ST2 is doing is abusing the concept.
Changing the language definition file(s) is not a solution for me.
Can we go to a simple token based solution where I can define the tokens and group them?
Please comment.
