Ok, so “hyperbole” aside - no offense taken  - there are really two issues here:
- there are really two issues here:
- Big files
- Long lines
SQL files have a habit of fitting into both categories, but there are any number of file types, which may or may not be used by programmers, sysadmins, researchers etc. that could be either or both.
Considering long lines, easier to demonstrate and the more pressing issue personally, we really don’t need a 500M file as @wbond put it to see usability going south (although, 500M really isn’t all that big these days?!) A 1M file will suffice for the purpose of illustration…
So creating a 1M ‘lorem ipsum’ on 1 line, Sublime text 3 portable build 3083, no plugins. I observe the following:
A. Word wrap off, ‘Plain text’ syntax mode, Find ‘highlight matches’ disabled:
- ‘Phase’ cursor pulsing animation is jerky and not smooth
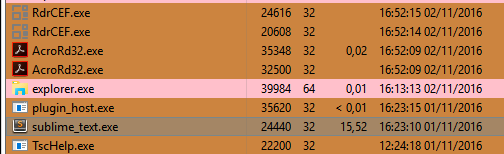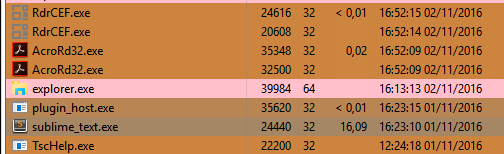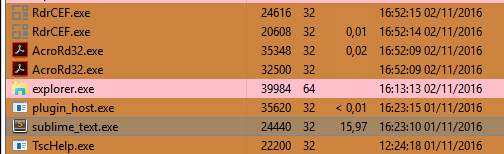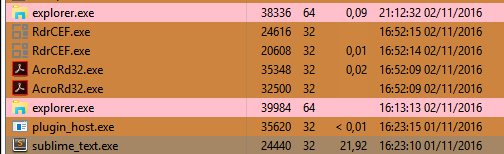
- CPU is at 25% on my quad-core system running at 3.5Ghz when idling
- All UI interaction with the keyboard is laggy and slow, even interacting with popups. Cursoring right a 0.5-1 second pause before the cursor reacts.
- Highlighting ‘sit’ and pressing Alt+F3 to highlight all copies (3000) freezes sublime for 5 seconds. Trying to move or type with these multicursors takes 5-7 seconds per keystroke. Phase cursor animation has almost completely stopped.
B. Word wrap on, ‘Plain text’ syntax mode, Find ‘highlight matches’ disabled:
- Cursor pulsing as expected
- CPU is 1-2% when idling
- UI interaction within acceptable parameters (no noticeable delays)
- Highlighting ‘sit’ and pressing Alt+F3 takes 2 seconds. Once all copies are highlighted cursor pulsing animation has almost completely stopped. CPU use is at 25% while idling. Cursoring right takes 2s before the UI reacts
Just viewing, scrolling and cursoring, let along performing edits in scenario (A) above is painful. And in many cases, when trying to do more sophisticated operations, Sublime will crash completely. Scenario (B) is more usable, but the moment we do anything with multicursors things get similarly bad.
Curiously, the situation with word wrap off seems much worse; Given that most of what’s going on is outside the viewport rendering area (even for the minimap) it appears that either Sublime is rendering everything all the time (without optimising for things that aren’t visible like cursors) or the data representation of editing objects could use some tuning. The irony being that with word wrap on, there is more visible rendering, especially with the minimap enabled. In both A/B cases, it feels like there’s room for improvement and optimisation.
In real world files, we may have many lines which are 100K+ in addition to many more short lines, and the situation is worse. Even with syntax colouring switched off, such files are a real PITA to view and edit with Sublime and your fingers are nervously hovering the keyboard in case something you do is going to hang or crash Sublime. By contrast, Crisp, Notepad++, Codewright, UltraEdit, VIM, gedit and have no such issues, and only start to feel the strain when files/lines get huge by today’s standards.