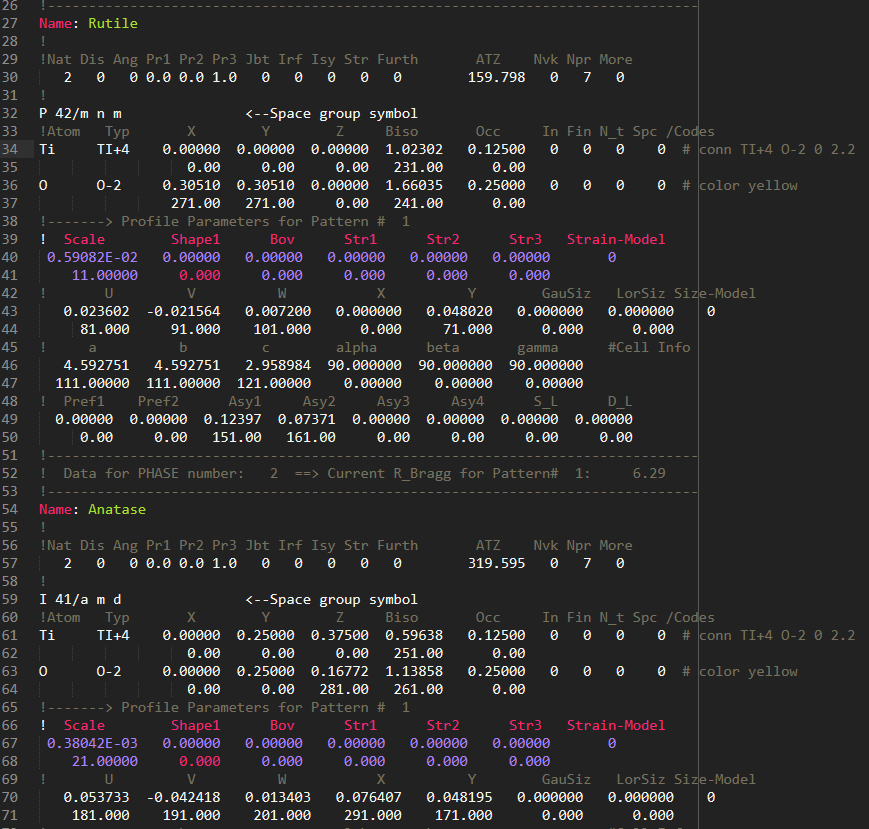
OK, just for my own masochistic delight I googled this thing and tracked down some PCR files and the manual. From what I can tell they are essentially data files that pass parameters to some scientific software written in Fortran. Each line contains a number of fields and beyond that they don’t have much of a structure.
BUT lines that begin with a ! are comments which actually makes syntax highlighting this pretty straight forward.
You’ll need to use the comment lines to tag each following line or set of lines that share a common set of columns (fields).
So if your syntax definition matches the comment line
! Scale Shape1 Bov Str1 Str2 Str3 Strain-Model
you know the meaning of these following lines
0.14336E-04 0.00000 0.00000 0.00000 0.00000 0.00000 0
11.00000 0.000 0.000 0.000 0.000 0.000
which would allow you to match and format them accordingly, until you encountered this line
! U V W X Y GauSiz LorSiz Size-Model
which would then trigger a different set of format matching for those kinds of columns.
The syntax highlighting system is actually designed exactly for this sort of thing, so if you familiarize yourself with it you will get the idea. But trying to do it without the comment lines isn’t going to work.
Note that you don’t need to use those exact comments, or match the entire comment line. Anything that uniquely identifies the lines that follow will work.