I’m working on a plugin-framework, part of which is a plugin that will allow developers to easily add auto-completions to their plugins.
##For example:
I have a module, Regions.py, which can be called by: R = Region.get_Data ( view, region )
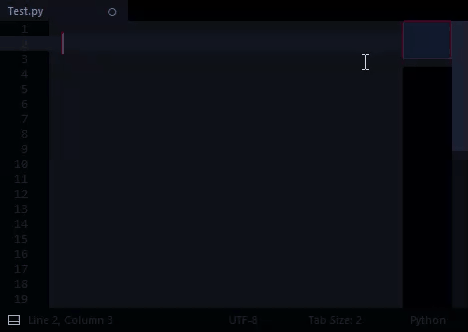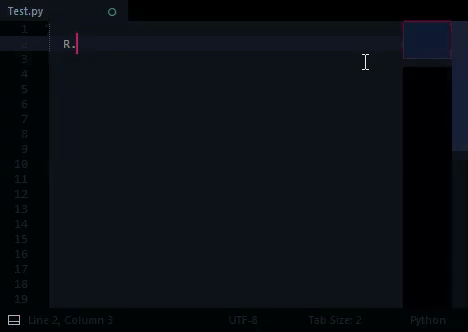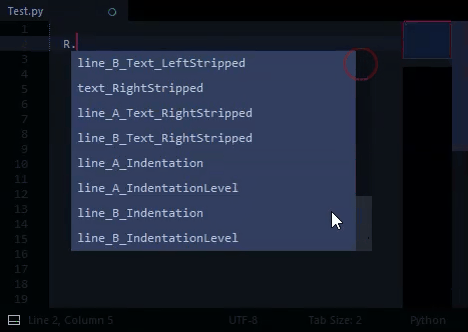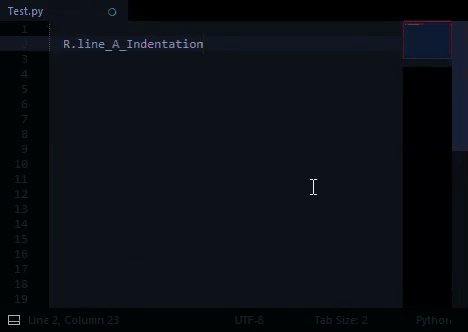
In my custom-completions file: I’ve included all properties of R, and set a fileExtension filter so that R properties only show as completions in Python files.
This works great, but I would prefer for the completions to show only after the separator character has been entered. This way, completions would be shown without the prefix. It would also prevent completions from being shown prematurely in the case of similar prefixes.
I’ve written a separate solution which can detect such cases:
The issue I’m running into is that on_query_completions closes the completion panel when any characters from sublime-settings/"word_separators" are entered, so I cannot implement the code from the second example.
Are there any workarounds for this?
Note: Modifying word_separators is not an option, as it would not work “out of the box” & could also cause issues with user preference & functionality.
An alternative solution I have in mind is to implement the code from the second example @ on_modified. To do this, I would need to be able to programmatically define auto-complete entries outside of on_query_completions.
I’m not entirely sure I’m understanding… When the user types R, it seems that at the moment, you are showing the auto complete, with entries starting R., am I right? But you want to just show the R-related auto complete items when they type R. instead and drop the R. prefix from the entries? Would it not help to just trigger the autocomplete on ., check what comes before it, and if it is R, show the relevant entries?
Can you share some code, it might help me to understand better?
side note: maybe a scope filter would be better than a file extension filter?
Can you elaborate on why it would be useful to implement?
Personally, I’m good with the file extension filter. I haven’t gotten into syntax & scopes all that much, and can’t think of a scenario where I would need a more precise filter.
However, I am considering adding it as a secondary filter, since it was included in the css_completions.py which I used as a starting point & it may be something others are interested in.
The first example that comes to mind would be so it can offer autocompletion on unsaved files. But more importantly, some file types have many different “sub-languages” like a PHP file can contain HTML, JS and CSS as well as PHP, and you want to ensure you offer the correct/relevant completions in the right places.
it might be worth taking a look at how I did it in the XPath plugin. You can set which characters should automatically trigger auto completion, and then further down it makes use of the cursor positions to determine what the desired prefix (i.e. including word separator characters) is. Hopefully that will help you
It’s cool that you can set the triggers programmatically for the input panel ( I’ll have some fun with that another day ), but I’m guessing that sublime-settings/"auto_complete_triggers" is the only source for on_query_completion. ( couln’t find any other info… )
I was hoping to avoid necessary configuration on the user side, but at least it works. Guess it’ll be on the devs to provide informative setup documentation. Still not a big fan of that implementation since it means users will have to manage settings for multiple plugins in a single value.
Good point, I guess I’ll go with a 3-tier hierarchy:
Scope
Syntax
FileType
That way, lazy people like me can just throw a filetype or syntax in, and anyone who needs more control will have some options.
Also, I think FileType is equally as important as scope, because it allows you to define separate completions for different filetypes that may share the same syntax.
Do you agree with my implementation of completionMode & completionGroup ?
The only completionMode that’s kind of tricky is scope
This seems to work fine, but I’d like your input just to be sure:
elif completionMode == completionMode_Scopes:
for scope in completionGroup:
rx_ScopeInScopes = \
"(^" + scope + "($|\ ))" \ # matches entire scope or first scope
+ "|(.*\ " + scope + "($|\ ))" # matches last scope or any scope surrounded in spaces
if re.match ( rx_ScopeInScopes, R.scope_B ): # R.scope_B is the scope @ caret region
matchFound = True;
looking good! there is a built in function view.match_selector which can be used for scope checking - that way, you can specify a scope like source.python - string, which will match if in a source.python scope but not in a string scope etc. Saves needing to use regex and keeps it consistent for developers expecting this functionality/behavior.
This can be emulated with the “selector” check using simply source.. And you can specify many different scopes like this: plain.text, source.python, so I would say ditch it. I do like the idea though - if this functionality didn’t exist, I would be singing your praises
I’m an avid YAML fan, so I’d recommend you to use that for human-created or -editable data. Additionally, I would abuse some “advanced” data structures to simplify it to the following.
completionSeparator: .
completionMode: Syntaxes # Global | Syntaxes | FileExtensions | Scopes
completionGroup:
- Packages/Python/Python.sublime-syntax
completionSets:
- [string, THIS IS A STRING]
- TestCompletion:
- PrimaryA:
- SubA1
- SubA2
- PrimaryB:
- SubB1
- SubB2:
- Nested1
- Nested2
I’m not sure how sub-completion discovery is supposed to work for completions where trigger and completion differ, but that is your problem to solve.
Furthermore, the “completion*” prefixes seem unnecessary since the file is, by extension, obviously already about completions. The term “group” is also misleading imo. I would rather use something like “syntax” or “context”.
My code currently tests only against the completions, since that’s really the only thing you can pull from the view.
Agreed. I didn’t like that I was using completionGroupandcompletionSets, but I couldn’t think of the right word.
Context is perfect.
I like how succinct it is, but I don’t like how non-visual it is.
For example:
- SubB1
- SubB2:
- Nested1
In a larger document, a ( missing ) colon @ SubB2 could be a hassle to find if your completions aren’t working correctly; whereas in a JSON document, it’s pretty clear & easy to see what the hierarchy is.
I haven’t worked with YAML yet, so I’ll play around with it a bit & see how it goes.
Currently, all of my loops are explicit:
for file in completionFiles:
for completions in completionSet:
for completion in completions:
for subCompletions in subCompletionSet:
for subCompletion in subCompletions:
The YAML example you provided is more dynamic than my original JSON template; which removes redundancy from subCompletions, and I’m guessing would also allow an unlimited depth of nesting.
Can you offer some insight ( and/or pseudocode ) into how I could go about achieving a similar result without explicitly separating completions from subCompletions ?
No. I would probably provide some pseudo-code for my proposal, but not for this weird split into main and sub completions.
But maybe you can find something useful here (building the data structure) and here (crawling for completions).
That’s what I meant.
( for the solution in your proposal )
My code for the completions & subCompletions approach is already 100% functional, as shown in the GIF demo above.
I haven’t worked with a recursive function of this sort, but I have a few ideas…
The one I’m leaning towards is splitting the lastWord @ caret region by completionSeparator, and digging into the ( single ) completions dictionary with each split string.
( or return the top level if no matches are found )
I’ll try it out when I resume working on this later today.
Thanks for your input & suggestions in the previous posts
I spent the last 2 days trying to implement the YAML conversion. While I was able to replicate the previously demonstrated level of functionality, I was unable to construct a working function to allow for arbitrary nesting.
I’m not too skilled with recursion yet, and in attempting to implement it I kind of hit a brick wall in regards to dealing with the complex nesting of arrays & dictionaries in YAML.
The closest I got was this script, which appends all nested entries from the YAML data to an array:
def run ( self, edit ):
...
for entry in yamlData:
self.get_AllEntries ( entry )
...
def get_AllEntries ( self, entry ):
global entries
if isinstance ( entry, dict ):
dictKey = list ( entry.keys() ) [0]
for key, value in entry.items():
if not isinstance ( value, dict ) \
and not isinstance ( value, list ):
entries.append ( ( key, value ) )
elif isinstance ( value, dict ):
self.get_AllEntries ( value )
elif isinstance ( value, list ):
entries.append ( dictKey )
self.get_AllEntries ( value )
elif isinstance ( entry, list ):
for item in entry:
self.get_AllEntries ( item )
elif isinstance ( entry, str ):
entries.append ( entry )
Although I was able to extract all of the YAML entries, it still didn’t help much as far as retrieving specific entries by key. ( especially performance-wise, considering my approach )
I’ve since reverted to my JSON model, and successfully managed to get recursive completions working with a pretty simple script which uses existing text to precisely query the JSON data:
# lastWord == all characters preceding caret until whitespace or BOL
# in the case of:
# lastWord == "TestCompletion.PrimaryB.SubB2"
# lastWord_Segment_Count == 3 == len ( lastWord.split ( "." ) )
for index in range ( 0, lastWord_Segment_Count ):
completions = completions[ lastWord_Segments[ index ] ]
# is effectively:
# completions[ TestCompletion ][ PrimaryB ][ SubB2 ]
# which returns:
# [ "Nested1", "Nested2" ]
Do you know of a simple way to apply a similar method to the YAML data?
My attempts so far have been pretty terrible performance-wise; I haven’t been able to get anywhere close to the efficiency shown in the JSON method above.
Considering the amount of potential completions, I definitely want to keep the filtering as minimal as possible. Do you think it’s possible for a mixed array & dictionary YAML filter to perform as efficiently as an all dictionary JSON filter?
Honestly, I don’t get your code. I simply do not understand what you want to accomplish. It seems like you are flattening the data structure into a single “list”, but that makes no sense because the nesting gets lost in the process and you can’t properly use it to provide context-specific completions.
(Besides, I find the way you are formatting your code and not following any consistent naming convention to be very confusing, but part of that is just me.)
I my proposal goes over your head, feel free to just not use it. I don’t currently have the time to write some sample code anyway.
That’s the furthest functional code that I managed. Beyond that, I tried integrating the
for index in range ( 0, lastWord_Segment_Count )
&
lastWord_Segments[ index ]
from my previous post in order to only append particular entries, but I wasn’t able to do it successfully beyond the first nested level.
Care to elaborate?
I’m not super versed in any particular language. I pretty much just have the basics of programming down & am working on expanding my skillset through SublimeText, Android, & AHK projects ( for now ). Def would apreciate any input
Check out PEP8, which includes the most widely known conventions for Python code. I personally do not follow all of them, but most. I especially dislike the whitespace characters around braces. Either way, variable names like lastWord_Segment_Count are a big no-no.
I personally prefer to read Lisp style, but use GNU as it is much easier to alter & maintain.
There are definitely some valid points within the guide, but many of them are purely based on personal preference & some are completely irrelevant due to the ability of editors like SublimeText to easily alter the mentioned preferences.
Combined with the fact that there’s a “Pet Peeves” section, it reads more like a rant than a style guide…
While I haven’t studied any particular language extensively, I have looked into general coding practices a fair amount.
It’s takes a very logical approach, reviews many commonly used standards, and rather than specifying opinionated requirements - it offers unbiased explanations and comparisons.
Some examples that I personally have taken to are:
11.1 Considerations in Choosing Good Names
[Page 260]
The Most Important Naming Consideration
The most important consideration in naming a variable is that the name fully and
accurately describe the entity the variable represents. An effective technique for coming
up with a good name is to state in words what the variable represents. Often that
statement itself is the best variable name. It’s easy to read because it doesn’t contain
cryptic abbreviations, and it’s unambiguous. Because it’s a full description of the
entity, it won’t be confused with something else. And it’s easy to remember because
the name is similar to the concept.
For a variable that represents the number of people on the U.S. Olympic team, you
would create the name numberOfPeopleOnTheUsOlympicTeam. A variable that represents
the number of seats in a stadium would be numberOfSeatsInTheStadium. A variable
that represents the maximum number of points scored by a country’s team in any
modern Olympics would be maximumNumberOfPointsInModernOlympics. A variable
that contains the current interest rate is better named rate or interestRate than r or x.
[Page 274]
Format names to enhance readability
Two common techniques for increasing readability
are using capitalization and spacing characters to separate words. For example, GYMNASTICSPOINTTOTAL is less readable than gymnasticsPointTotal or gymnastics_point_total.
[Page 288]
Names should be as specific as possible. Names that are vague enough or general
enough to be used for more than one purpose are usually bad names.
…
…
Code is read far more times than it is written. Be sure that the names you choose
favor read-time convenience over write-time convenience.
On the topic of whitespace, I’d argue that it makes code much easier to read & scan through quickly.
( with less mental & visual processing effort )
For example:
Which of these is easier to parse for a specific rock?
[ 1 ]
[ 2 ]
If it’s just once, it’s not a big deal; but if I had to sort through 100s of groups on a daily basis - I’d most certainly go with the first style.
( I’m uber lazy when it comes to mental energy expenditure, gotta save my focus for actual coding problems )
I know there are a ton of debates on coding style, just thought I’d share some of the logic behind mine.
( along with some helpful resources, hopefully )
re lastWord_Segment_Count: It mixes three different naming styles. camelCase, snake_case and TitleCase (for the underscore-separated words). Choosing good variable names does not matter if you can’t remember how you separated the sub-words from one another.
Python’s stdlib uses snake_case for most modules (cept the likes of unittest, which haven’t been migrated to the style yet), so using snake_case for your own code comes only naturally.
Python does not use K&R style because there are no braces for blocks in the syntax. You may use round braces to group statements.
That said, of course most of the conventions are going to be opinionated and some are not the best choices for each, but the most important aspect here is consistency. I read a lot of code and that code following the same style is a lot better for me than each programmer having his own take on “what is readable or not”. Even if the choices may be slightly sub-optimal, the fact that the style remains the same across code bases helps immensely.
I also do not agree with your stone example. The images show stones as the smalles entity (atomic), but code can be tokenized into groups, such as function calls, attribute or item access and treating those the same was as binary operands (surrounded by spaces) does not improve readability but makes it harder to grasp the extends of such tokens. To get back to your example: Think of it as stones of the same color or type being grouped while separated from the other groups and the task being “count the stones of each type”. Besides, you don’t wrap the accessor operator (.) with spaces either, do you?

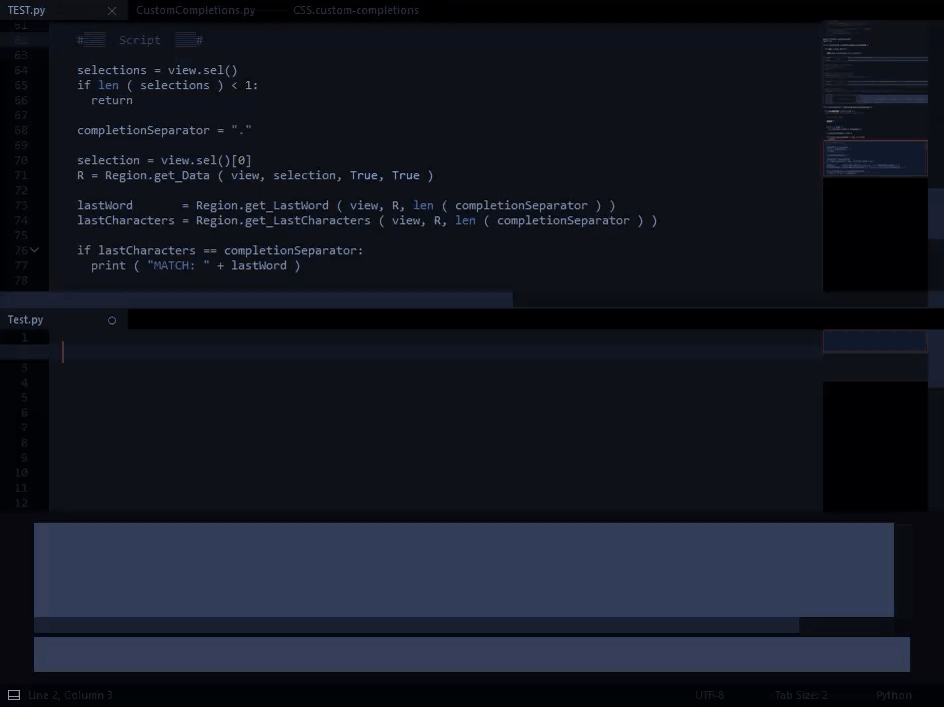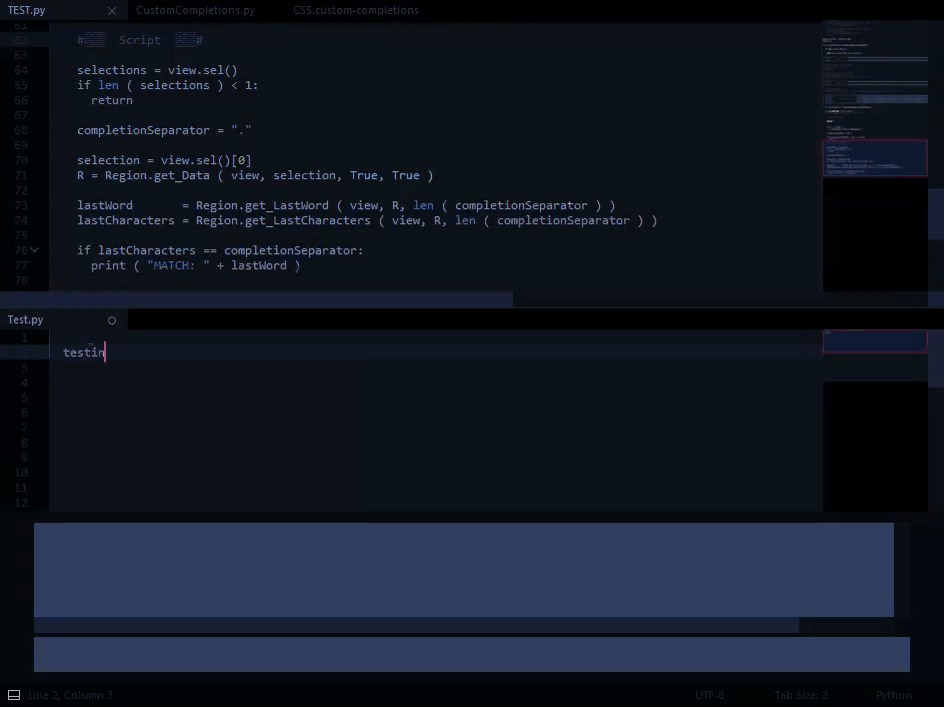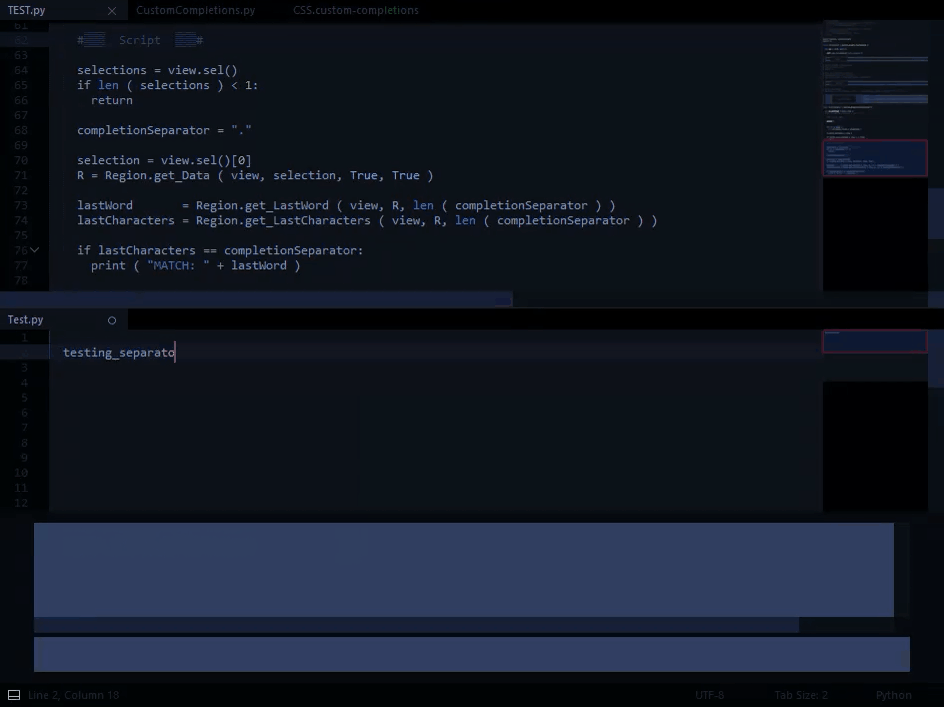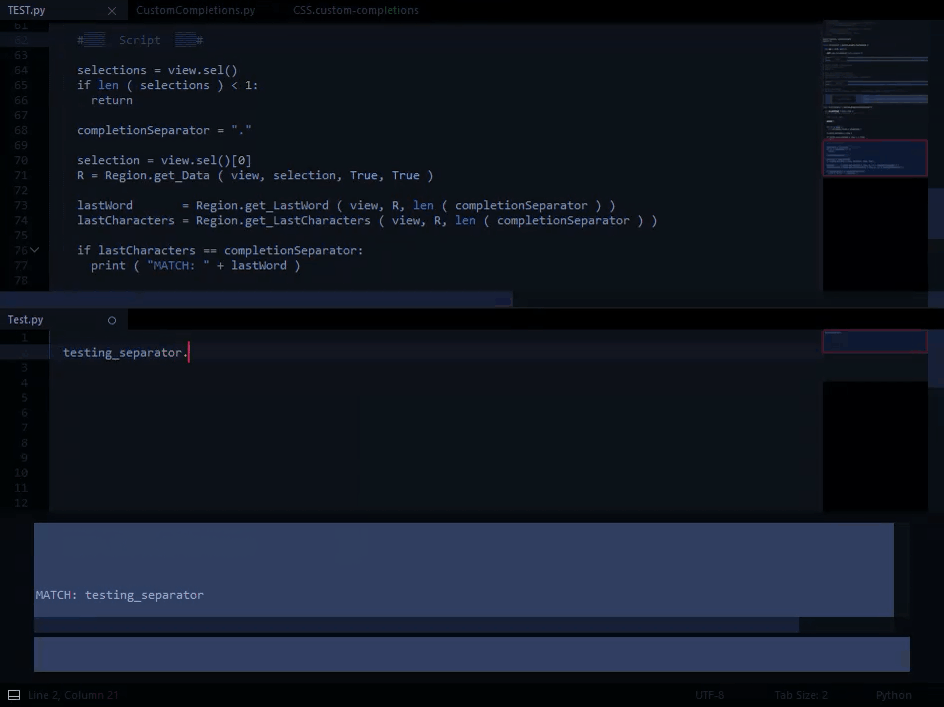


 ), but I’m guessing that
), but I’m guessing that 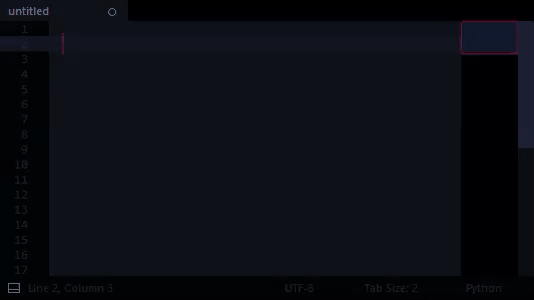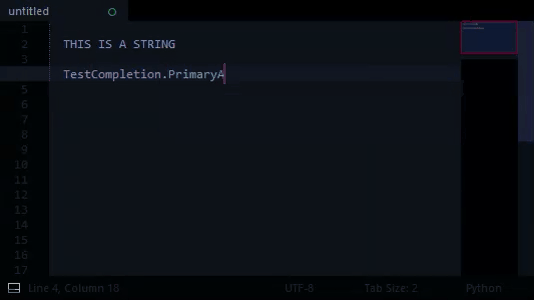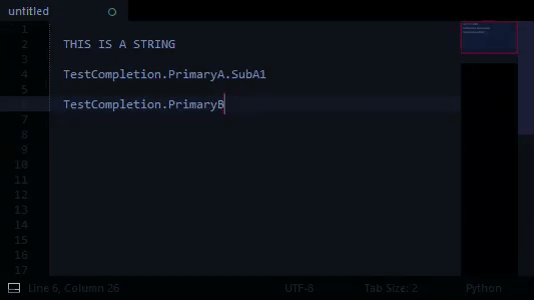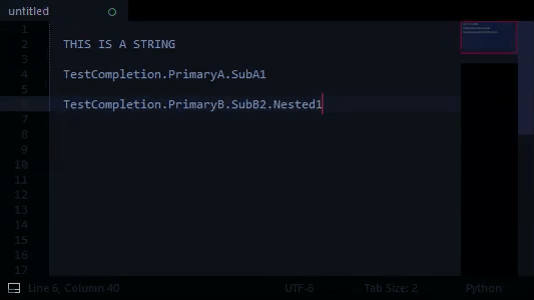



 )
)