Oniguruma is the old engine. It’s a general-purpose regexp engine that supports features like backreferences that aren’t actually “regular” in the technical sense. It uses (I presume) a backtracking implementation that can run into performance issues in corner cases. Possessive quantifiers make it easier to avoid these cases, and they fit naturally into a backtracking engine.
The new engine, sometimes known as “sregex” (but not the same as the open-source engine of that name) was written specifically for Sublime Text. It is optimized for use with Sublime’s syntax highlighting system. It is a true regular expression engine, meaning that it does not implement backreferences or other non-regular features. I presume that it is implemented using state machines, which work in guaranteed linear time and can be combined to match multiple regexps simultaneously. Possessive quantifiers would not make such an engine run any faster.
Documentation for the engine is sparse; my understanding of it is based on various statements from the team and on my own knowledge of regexp engine implementation. The big features that will almost certainly never be implemented are backreferences and lookbehind. These features are fundamentally incompatible with the design of the new engine. It’s possible that named captures could be implemented someday, because that’s not really part of the matching engine itself but could be handled early when processing a regexp. Possessive quantifiers could be implemented (I think), but because they mostly exist to work around performance problems in backtracking parsers there is no reason to use them with the new engine in the first place.
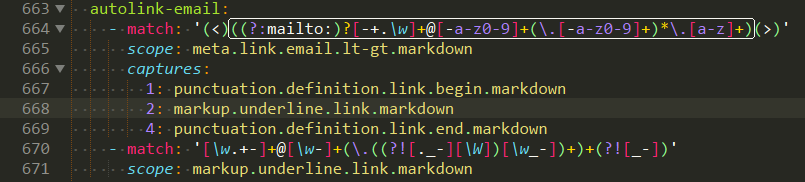
There’s a built-in build system: “Syntax Tests - Regex Compatibility”. This will tell you if any of the regexps in your syntax are incompatible with the new engine. Such regexps must be processed using the older, slower engine. Because you’re using backreferences to account for indentation, it is impossible for the syntax you’re working on to be 100% compatible with the new engine. I believe (but have not verified) that any context with only compatible regexps should still be fast. Fundamentally, Sublime’s parser is only designed to recognize deterministic context-free languages, which can’t handle indentation. In some cases, you can use backreferences to handle such things. This is a trade-off between functionality and performance.