There are two ways you can do something like this (and this works in all of the find panels; Find, Find/Replace, Incremental Search, Find in Files, etc).
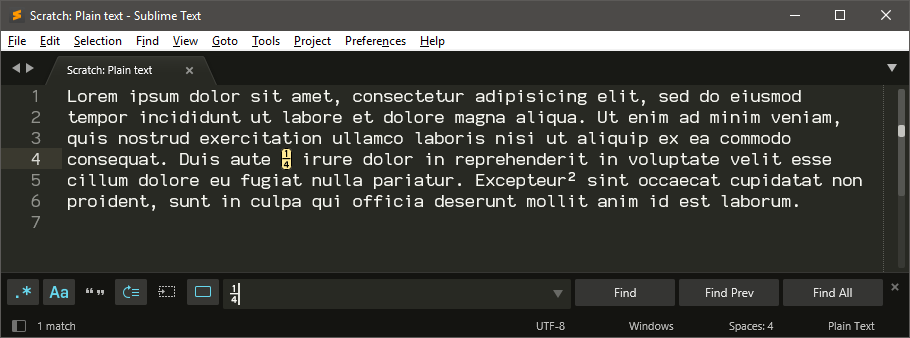
The first would be to paste the character that you want to find directly into the search field in the Find panel:
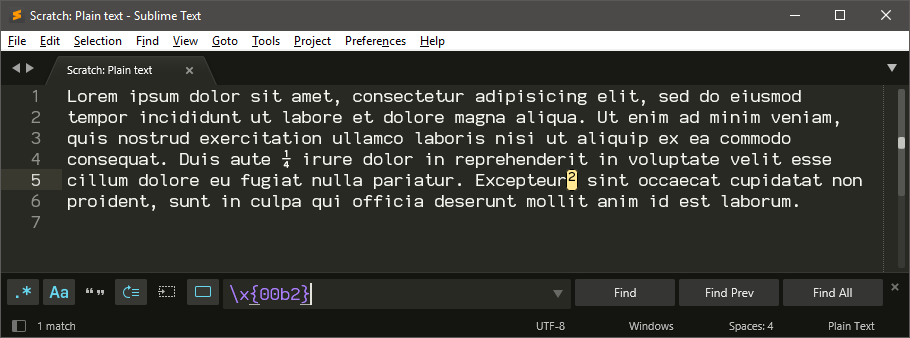
You can also search for a Unicode code point by using the sequence \x{####}, where the #### is the Unicode code point for the character that you’re interested in looking for. This information is available from the Character Map tool when you hover the mouse over a character.
For example, the Unicode code point for Supercript Two is U+00B2, so you can search that way as well:
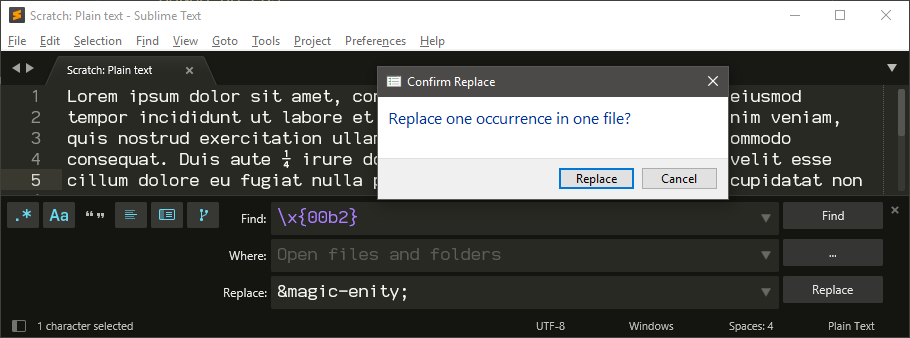
As noted above, this also works in Find in Files as well, so you could use that mechanism to search a large group of files and do the replacement that way (though you would need to do it one character at a time):