Yes, what Narretz says is true. I believe Jon significantly improved the performance for large files if you switch to “Plain Text” syntax in ST3 so that it does not need to use regex (that is what syntax defs use) to parse the file.
Sublime Text performance with very large files
qgates
#4
I believe it is mostly to do with syntax colouring. Sublime along with textmate are both particularly sophisticated in this area, allowing things like context specific colouration / syntax selection. Both are slow with large files, due to their heavy dependence on regexs. In addition, Sublime has the minimap which requires everything to be coloured correctly in realtime, making lazy colouring more difficult. Large edits on large colourised files will be particularly slow, as will undos, and large amounts of multi-cursor edits will exaggerate things. Forcing sublime to turn off colourisers with “plain text” should speed things up alot.
Sublime 3 has improved in this area, though it would be nice to be able to disable colouring by default in certain situations (per session ie. View… disable auto colourising) or to make this a setting available as either a global, per-project or per-file setting. Rather than doing it “after the fact”.
I wonder if S3 has moved to doing this on a background thread (or will), so you can get working with your large files right away while the thread parsers through and applies the colouring. From what I’ve gleaned, the symbol indexing thing only happens when folders are added to the project, so this shouldn’t be an issue if the project’s empty.
1 Like
unphased
#5
There should be a simple configuration option (an integer number of bytes. Say, 1010241024 or 10MB) which either controls whether a file above that size will not have syntax regexes applied, or for which all files only get syntax regexes run over that initial segment of the file. So say you have a 30MB file with this setting, only the first third of the file gets highlighted.
I have already noticed a limit of this sort which ST3 applies to very very long lines. It will refuse to syntax highlight lines that are longer than some particular length. This may or may not be limited to XML files which was what I noticed this on first. We need only to extend this concept to the lines of the file itself.
1 Like
diathesis
#6
Just loaded a 500MB file to check – 50s by stopwatch (with human error on start/stop time, of course), with no indication what’s going on that I can see. Tolerable but not great. Less is instant, and Atom crashes, by comparison. Could be better, could be worse.
1 Like
diathesis
#7
On a 50MB file, Atom is actually slightly faster, and does warn about the large file, so you have some idea of what’s happening.
1 Like
qgates
#8
Something I need to do now and then is make S&R changes to SQL files for databases generated by CMS’s like Joomla and Wordpress. Both PhpMyAdmin and MySQL dump generate SQL files with long lines (sometimes over 1000 characters); I had to edit one today and this is where Sublime struggles.
On such files, Sublime becomes quite unresponsive, with a noticeable delay / high CPU when moving the cursor around, paging up/down through the file etc. I’m running a powerful machine here, so I can only imagine how bad this would be on a more ‘typical’ i5 or core2 laptop.
I do feel that this needs attention in Sublime. Today I got by, but there are times when this is a showstopper and most other pay-for professional editors have no issue handling either very large files or files with long lines. Doubtlessly this is down to the editing engine design but I’d love to see some work on the core to improve this.
1 Like
barth
#9
I thought of writing a plugin to switch syntax to plain text but there does not seem to be something like an on_preload hook.
0 Likes
wbond
#10
Do you have wordwrap turned on? If so, that can cause a huge difference. With a large file containing hundreds of thousands to millions of lines, each line has to be checked to see if wrapping will happen and how it will affect the current viewport into the file. Without wrapping turned on, the viewport offset is much simpler to calculate.
3 Likes
gwenzek
#11
“on_new” is often called before the file is done loading so it might work.
EDIT: I meant “on_activated_async”
1 Like
addons_zz
#12
Very bad things to do:
- Do not warm the user.
- Do not show a loading progress bar.
- Do not allow to cancel the operation, if not kill the the whole process.
If sublime just freezes, it means the work is being done on the main GUI thread. I am not saying to spam a new thread when opening a new file, just call one dedicated thread to perform secondary operations.
Related core issue:
- #1463 _ Packages are allowed to hang Sublime Text Indefinitly
0 Likes
qgates
#13
No, word wrap is off. With wrap on it’s completely unusable. I am aware of the tricks needed to make sublime more bearable with large files / long lines, like turning wrap off, switching to plain text (no syntax colouring), turn off ‘highlight matches’ for search etc. It’s usable but sluggish, and the bigger the file / longer the lines, the worse things get.
The best solution would be to rework the editing or rendering core somewhat as my suspicion is that the issues lie there but in the absence of that, progress bars, warnings and opportunities to cancel anything that’s taking too long would be a definite plus.
I wonder, is there any chance that this will get some attention? It’s really frustrating!!
2 Likes
wbond
#14
There is definitely a progress bar built in when loading large files. Are you using the default theme?
Generally there is a lot of the editor that is implemented to make it a good code editor. Text has to be split into tokens to allow keyboard navigation, highlighting, indexing, symbol list, word wrapping, etc. Rewriting all of that so that it is possible to disable the majority of built-in functionality for the sake of opening a 500MB file seems to me like a generally unproductive use of time, in the grand scheme of all of the things that could use improvement and bug fixes. Plus, I imagine different users have a different idea of what functionality is essential that they would want preserved when editing a large file.
2 Likes
addons_zz
#15
Eclipse IDE asks the user whether they want to disable all extra features as syntax highlight, word-wrap and etc, before opening a big file. So the user may choose whether to wait more and get all features, or open early with no extra features. Sublime could do the same.
Yeah, Sublime text has a loading bar, I tested opening 1GB file, and it allowed to cancel closing the file hitting by ctrl+w.

For 1GB file, it required a little more than 1GB of RAM’s Memory. But right after filling the progress bar, Sublime Text hanged for 20 some seconds. Then after it became responsive, I tried to interact with the file and Sublime Text hanged using all its CPU.
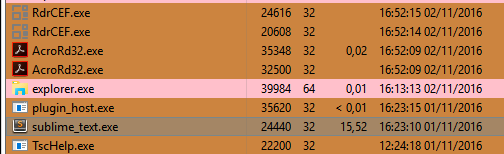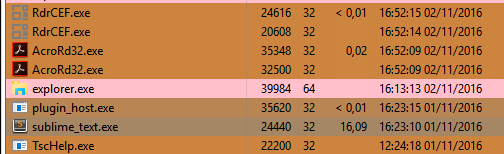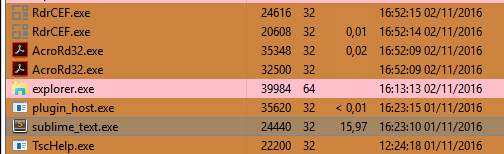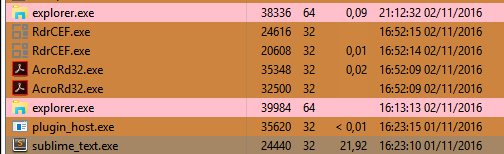
For now, 5 minutes has passed and it still hanging, so I am killing the process. This 5 minutes hang after opened the file is because of issue #1463 Packages are allowed to hang Sublime Text Indefinitely.
Because when I did the same on a Vanilla Install, Sublime Text only hanged for 20 seconds right after the loading bar got filled. After it It was completely responsive! Good work. Now we know Sublime Text may handle 1GB files, but only the Vanilla version, because if there are more packages installed, they will hang Sublime Text due the issue #1463 Packages are allowed to hang Sublime Text Indefinitely.
0 Likes
gwenzek
#16
I try to write a plugin to improve this:
MAX_SIZE = 1e6
class OpenBigFileListener(sublime_plugin.EventListener):
def on_activated_async(self, view):
file_name = view.file_name()
if not file_name:
return
size = os.stat(file_name).st_size
print('File', view.file_name(), 'has a size of', size / 1000, 'Kb')
if(size > MAX_SIZE and view.is_loading()):
view.set_syntax_file('Packages/Text/Plain text.tmLanguage')
settings = view.settings()
settings.set('word_wrap', False)
But it seems the syntax is changed back to the original syntax after loading.
1 Like
djspiewak
#17
One of the things I’ve seen in other editors is a “fallback mode” paired with clever windowing on syntax highlighting. Procedurally, the editor starts by using the fallback mode to highlight the file. Fallback modes are not allowed to have context, their regular expressions must be free of all backtracking, and everything has to be line-bounded. Basically, it’s simple tokenization and nothing more (note that this will mishandle tons of common constructs, including multi-line strings).
Then the editor attempts to refine the fallback mode with the main mode, but bounding as much as possible within the active view subset of the file (plus/minus some reasonable expected scrolling). With modes that have neatly-closing contexts, this actually works out fairly well. For example, imagine the active view is in the middle of a class body, with the class starting just above the view and ending just below. The class body will pop most of the active contexts off the stack, and you’ll end up with just source.whatever. You can defer applying the full highlighting to the text above and below the view. There are clever ways to extend this to certain forms of contexts as well (e.g. situations where you don’t have things neatly popped off above and below), but you get the idea.
The main thing you lose here is symbol indexing, since you can’t ever fully-contextualize the entire file. I don’t think that would be a surprising loss for most people, especially if it is accompanied by a warning (e.g. a banner at the top of the view, indicating that limited highlighting is in effect, with an option to turn on full highlighting at the cost of performance). You do get to keep the minimap, which is sort of fun, though it will have limited accuracy outside the current view (and for that reason, it might be better to disable it on such files).
Obviously, this is certainly a significant amount of work that may not have value, and might even (depending on implementation) require backward-compatible changes to modes to work optimally. But it does allow for opening and editing enormously large files.
1 Like
FichteFoll
#18
We already have most of this by default. Granted, syntax definitions may still use backtracking, but it’s much slower and there are tests to ensure your syntax definition does not contain backtracking expressions.
Although contexts may span multiple lines, I doubt it impacts performance much since the overall work done is still very similar and the entire file is almost never re-tokenized entirely after it has been once due to smart caching.
Edit: The one thing ST wouldn’t be able to do currently is start lexing in the middle of the file for the first time. It must load and tokenize the entire file first before caching can help.
2 Likes
qgates
#19
There is a progress bar when loading, but anything that may be time consuming to the point of locking up Sublime has neither progress indication nor the facility to abort.
I have worked on editor codebases in the past (most of my development life is C/C++) so I understand the complexities involved generally. Obviously, I can’t comment on Sublime as I have no knowledge of its design or implementation. I can’t be the only programmer / technical user that needs to work on large files or files with long lines, and the fact is I can’t use Sublime for many of these tasks. Moreover, I can work on same with almost any other half decent editor. Falling back to another editor isn’t the end of the world, but is nonetheless frustrating.
Apart from anything else, it just doesn’t look good. Sublime is sold as a general purpose, high performance editor, but starts to feel flaky when you throw something substantial at it. I don’t share your view that addressing such issues would be a waste of time: making the editor robust under all circumstances shores up its reputation as the first choice in high performance, powerful editors for all tasks. Case in point: Photoshop. It doesn’t break when you load up huge images. It feels robust. It warns you when something’s going to take time and doesn’t lock up. It’s UI rarely falters or gets ‘slow’. Ergo, the go-to tool for pretty much anyone needing to edit images professionally.
Don’t misunderstand me, this isn’t a rant: I love Sublime and continue to use it daily. But the value proposition is problematic for some when they have to switch between numerous editors for no good reason. We all want Sublime to improve and I see this as one of its limitations. Admittedly one that may not be the most straightforward to fix.
2 Likes
wbond
#20
I think this issue needs some more specification. Right now what I am hearing is that large file handling is completely broken, whereas that feels to me (based on my experience) like a little bit of hyperbole. Certainly there are areas that could be improved, but let’s identify some specifics so we can move the conversation forward.
I should note I am using a 2.3GHz rMBP from 2013 with 16GB of ram and an SSD.
I just opened a 5GB PostgreSQL dump with 45M lines. It took a while to load and tokenize from disk. There was a progress bar and a way to abort.
Hangs I experienced:
- After the file was loaded from disk (1-2 min?) Sublime Text became unresponsive for about 20s
- When changing from word wrap mode to non-word wrap mode there was a hang
- Trying to apply the SQL syntax (my machine paused Sublime Text after memory was exhausted)
Otherwise (with Plain Text syntax) I was able to scroll effortlessly through all 45M lines and move the cursor around without any lag whatsoever. This was true with word wrap on, also. Sublime Text was using around 10GB of memory.
Perhaps the solution is:
- Figure out the lag after the file is loaded
- Prevent anything but Plain Text syntax for 100MB+ files, and disallow word wrap (just to prevent the lag of switching it)
Currently there isn’t a way to detach the display of the file with the in-memory representation. When a syntax is applied, the file must be retokenized and have scopes applied. It would probably make sense to trigger a progress bar here. Without doubling memory usage, it wouldn’t really be possible to keep the old tokenization in-memory, so canceling would have to retokenize with the Plain Text syntax.
Are there other situations where you see Sublime Text hanging that aren’t caused by a third-party package? I’ve seen mention of ST being unresponsive navigating a SQL dump. Perhaps someone has some SQL dumps they are experiencing lag with that I can look at? Are you moving the cursor around, or typing? Are you typing a character such as a double or single quote when you experience the lag?
For a 24MB SQL file loading happened in < 1s and applying the SQL syntax happened in under 2s (with a hang). There were 84k lines, with many over 1000 chars long. Editing was perfectly fluid.
4 Likes
Open Source Sublime Text
Sublime runs very slow after reading large file
barth
#21
IMHO, I think this is an issue but not one that too much time and effort should be spent on. ST is aimed squarely at devs and coders and most source files are small. The huge files we are talking about are likely logs or data dumps. It’s mainly the inconvience of having to open another editor, or accidentally opening a huge file and have it hang ST.
With that in mind, I think it’s enough for ST to fall back into some “safe” mode, no syntax coloring or word wrap, and perhaps no packages outside of the defaults. You can add a view.is_safe_mode() method to let plugins know if safe mode is active and decide whether they want to run, or perhaps you can require plugins to declare themselves okay to run in safe mode somehow, meaning plugins are not safe by default.
And of course user can set a size threshold to trigger safe mode, and manually force normal mode when needed.
4 Likes
wbond
#22
Packages are loaded into the plugin host, so it won’t be possible to disable them for a specific view. It would require either another sheet type where various API features were not available, or some sort of opt-in system where plugins would choose not to operate on large files. The later option likely wouldn’t do much, and the former would require a bunch of work to interact with the current API in a way that didn’t lead to lots of Python errors.
1 Like