hello. I just find a problem on a forum, can anyone give me a help please?
Wanna change this with regex:
table TAB tisch
table TAB tabelle
into
table TAB tisch, tabelle
hello. I just find a problem on a forum, can anyone give me a help please?
Wanna change this with regex:
table TAB tisch
table TAB tabelle
into
table TAB tisch, tabelle
Search for \n and replace it with , (regex)
Or select the lines, press ctrl+shift+L, end, , and del.
Either solution won’t play nice if you have multiple blank lines though.
this is my regex, and will merge all lines. The problem is that this will not cut (delete) the words that repeats.
Search:
\s+(.*?)
Replace with:
leave space
Ah! Now I understand your problem. AFAIK, regex is not aware of the words per se, so you cannot do this automatically.
So you’re stuck with multiple steps; if lines are somehow aligned, you should be able to fix it with multi-selection.
actually, someone gives a solution for the example above. But does not generally apllies:
Check the extended option on:
Search:
\r\ntable TAB
Replace with:
with a comma or the separator you want.
For the specific case of your sample input, the following regex does what you want:
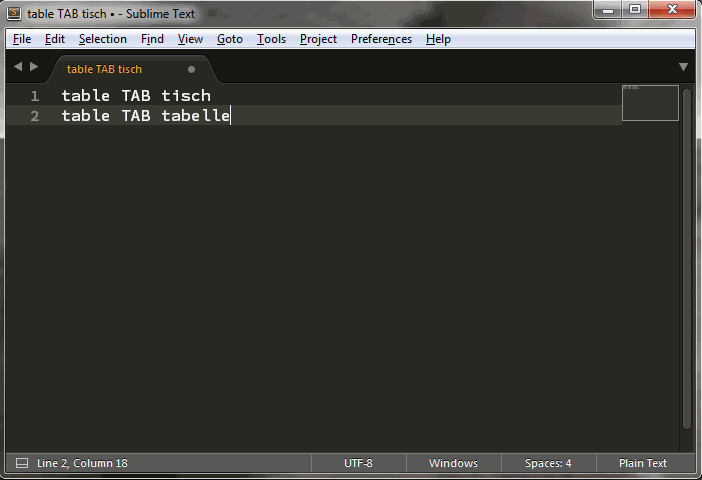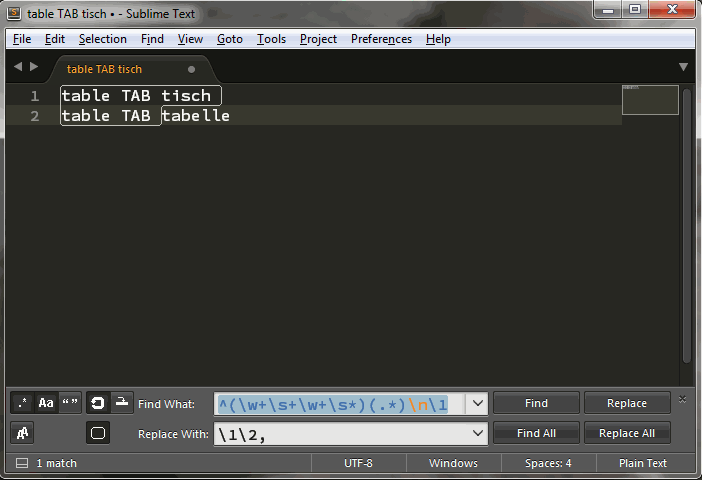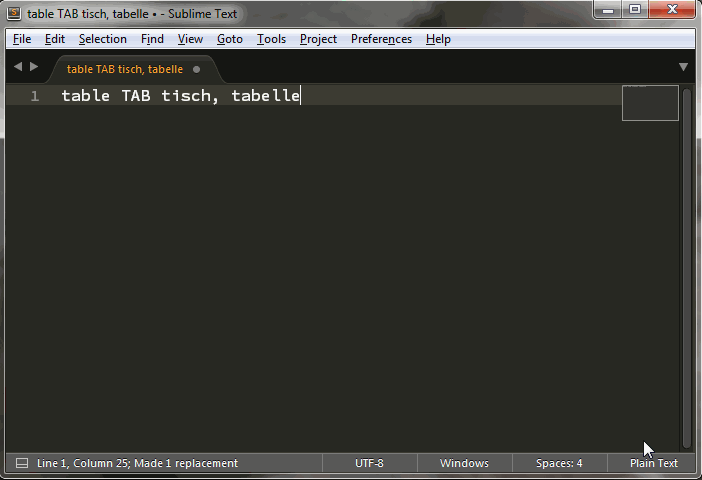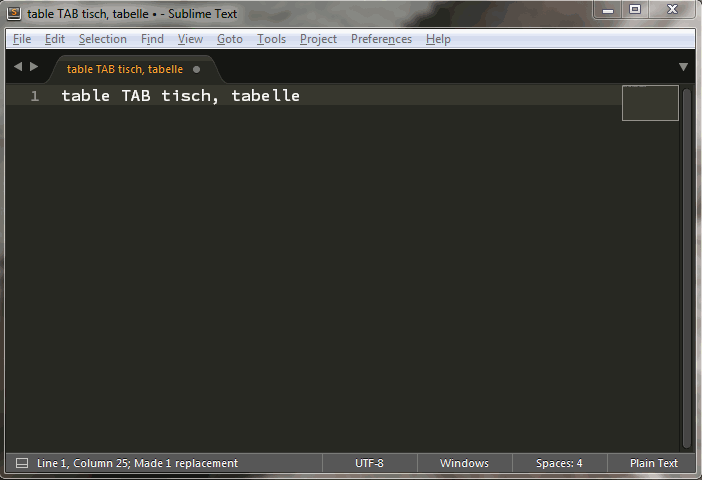
Find What: ^(\w+\s+\w+\s*)(.*)\n\1
Replace With:: \1\2,
***Note:***: there is a trailing space character on the replacement text
By way of explanation, this matches using two capture groups; the first group matches what you expect to be the common text on both lines while the second group matches the remainder of the first line. We then match the end of the line and the first capture group. The result is a capture of the entire first line and the common prefix at the start of the second line.
Then for the replacement we can insert both captures (which is the entirety of the first line); this replaces the original first line, the newline, and the common prefix on the second line.
I’ll leave it to greater minds than mine to rework this to be able to match on an arbitrary number of lines instead of just two, though (assuming that is actually possible, that is). 
thank you OdatNurd, works super. There only be one small problem, when I try to use this regex on ther example.
bördelversuch flanging test
bördelversuch folding test
When I use your regex, the f letter from folding word, disappear. Don’t know why.
See a print screen: https://snag.gy/rpfPzh.jpg
I said the regex would work for your specific example, and in your example both lines started with two identical words. In your problem text, the two lines start with only a single identical word, which is why it doesn’t work.
More specifically, if you modify the second word in the second sentence to something like “flaolding” and run it again, you will see that the “fla” is being tossed off of the second word instead of just the leading “f”.
This is an indication that the \1 in the regex is matching only as much of the first capture as it can; the match stops when the text stops matching.
If the problem is that it should do nothing in this case, you can append a + to the end of the regex; that will make it match only whole matches (technically one or more matches).
It sounds like what you want is for it to match only the first word in that case. However that would require crafting a regex that somehow has prior knowledge of how much of the line is supposed to match (so that it can capture only the duplicate parts).
I know of no regex construct that does that, but your brain knows what the matching text is, so one way around that is to modify the first capture to match what you want to remove from the subsequent lines.
hello OdatNurd. I don’t know what you mean with a + at the end of regex. Sorry, I am not a good programmer. Can you be more specific please?

{kind=link}