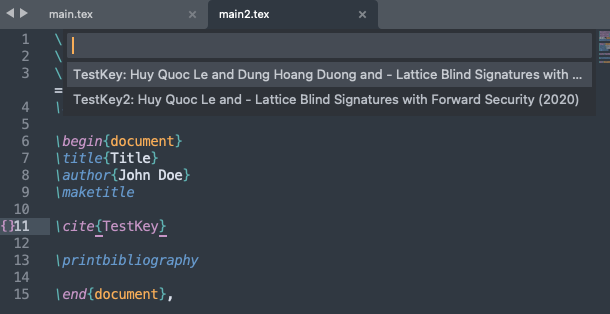
I have tried the same tex file and the same bib file (the one without the #), and I am still getting the same behaviour with authors cut off after the line break.
This also seems to be independent of the bibtex backend, same behaviour for bibtex and biber.
I am using Sublime Text Build 4126, Stable Channel, with recent installs of LaTeXTools and LaTeXYZ, running on MacOS 12.3.1 Monterey.
It seems that the program parsing the .bib file stops reading after a line break.
If this would only be a display problem, I’d accept it. One could argue that truncating the list of authors even makes sense, to have more space for the title. However, since the authors are truncated I also cannot search for names of 2nd, 3rd, … authors, which is really a problem because often I do not remember the name of the 1st authors, but that a paper was co-authored by someone, and thus this makes LaTeXTools on Sublime Text not well usable for me…
Does anyone have an idea where this parsing of the bibtex file happens, so that I can check the code there?